1. Overview of ML Analysis Platform Functions
To facilitate data analysis and model training within the RAInS project (AI Accountability System Project: RAInS Project Website), a machine learning analysis platform will be developed in Python. This platform will support data analysis and modelling, offering features such as a web-based user interface for interaction. It will include functionality to select datasets from local files, automate visual analysis, perform regression and classification analyses, view training logs, examine model parameters and results, and visualise outcomes. Additionally, it will generate the required JSON files, predict new datasets, and offer advanced functionalities such as anomaly detection and association rule mining.
2. Framework and Required Python Packages
Please install the necessary Python packages via Conda or Pip before using the platform.
1 | import os |
3. Program File Directory

- data: Stores the training and testing datasets.
- logs.log: Records the log information generated by the platform during operation.
- mlruns: Manages machine learning experiment logs and training records using MLflow.
- main.py: Contains the main program code for the machine learning analysis platform.
4. Design and Approach
(1) Initial Concept of the Program
Initially, I aimed to implement a data flow that could capture the machine learning (ML) process, including information such as training data, whether the data was pre-processed, the real data input into ML after deployment, and ML’s predictions. Additionally, I aimed to gather information regarding runtime anomalies (e.g., memory overflow or CPU overload), hardware errors, real input data formats, and data abnormalities. These records would be saved as JSON files to serve as an interface for other parts of the project. I initially used OpenCV to capture camera information, object movement times, and anomaly details.
However, I soon realised a significant limitation: using specific machine learning models with bespoke methods and parameters would not yield a general solution. Since machine learning does not employ a uniform template for all tasks, finding a general approach that could accommodate a specific method as a subset became necessary.
(2) Program Design
Machine learning relies heavily on data science methodologies. I used UCI datasets to source the required data and allowed developers to define these datasets independently, utilising pandas-profiling for data definition, analysis, and visualisation. The generated reports were stored as JSON files to assist engineers in model development and accountability.
The machine learning process generally involves collecting data, exploring and pre-processing the data, training the model, evaluating it, and finally optimising the model.
For the machine learning analysis, I used the pycaret library for modelling and analysis, employing regression and classification techniques. The program starts by extracting all column names from the dataset, enabling developers to select the desired features, followed by selecting appropriate algorithms based on the task. The entire process, including the logs, is saved in the logs.log file using pycaret.
To manage the models and track predictions, I employed MLflow (MLflow Website). MLflow’s Tracking feature records parameters and results from each run, providing visualisations of model performance. Conveniently, MLflow is already integrated with pycaret, allowing seamless management of training records and logs during execution. Developers can access detailed information by invoking the load_model function, and only need to provide a dataset to complete model predictions.
MLflow is an end-to-end machine learning lifecycle management tool developed by Databricks (Spark). It offers the following features:
- Tracking and recording experiment processes, enabling cross-comparisons of parameters and results (MLflow Tracking).
- Packaging code into reusable formats for sharing and deployment (MLflow Projects).
- Managing and deploying models from various machine learning frameworks to a wide range of platforms (MLflow Models).
- Providing collaborative management for the entire model lifecycle, including version management, state conversion, and data annotation (MLflow Model Registry).
MLflow is independent of third-party machine learning libraries and supports all machine learning frameworks and languages via REST API and CLI. To make usage easier, SDKs are provided for Python, R, and Java.
For visualisation and UI interaction, I used Streamlit (Streamlit Website). The Streamlit library contains components that meet the needs of most developers, enabling easy HTML design and web UI deployment with single-function calls.
Streamlit is a Python-based visualisation tool that generates interactive web pages. Unlike Django or Flask, Streamlit is not a complete web framework but focuses solely on visualisation.
The platform’s UI design is shown below:
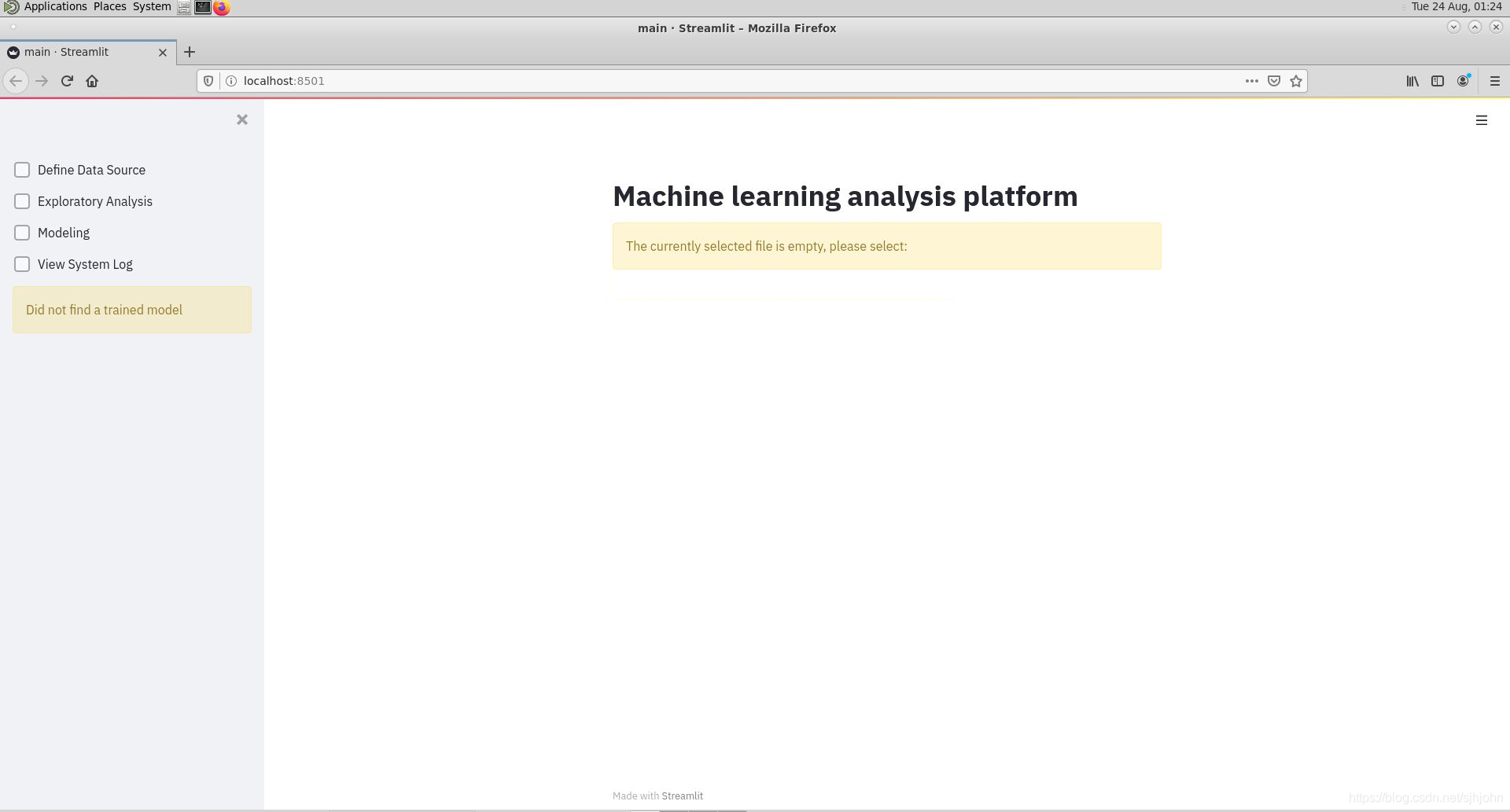
5. Functionality Overview of the ML Platform
(1) Project Deployment and Dataset Analysis
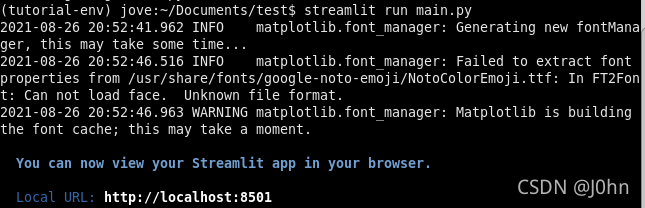
First, clone the project from GitHub to your local environment using git clone. Use pip or Conda to install the required Python packages. Write or debug the program using a Python IDE. Use Streamlit to run the main.py program by entering 'streamlit run main.py' in the terminal. As shown in the image below, port 8501 will be opened (with a local URL and a network URL), allowing you to access the UI page through the browser.
In the browser interface, you will see four functionalities on the left-hand side: “Define Data Source,” “Dataset Analysis,” “Modelling,” and “View System Log.” The user needs to place the dataset in the ./data directory, and they can select the desired model for machine learning training. Users can also specify the number of rows to be read and visualise the dataset by generating a report, as shown below:
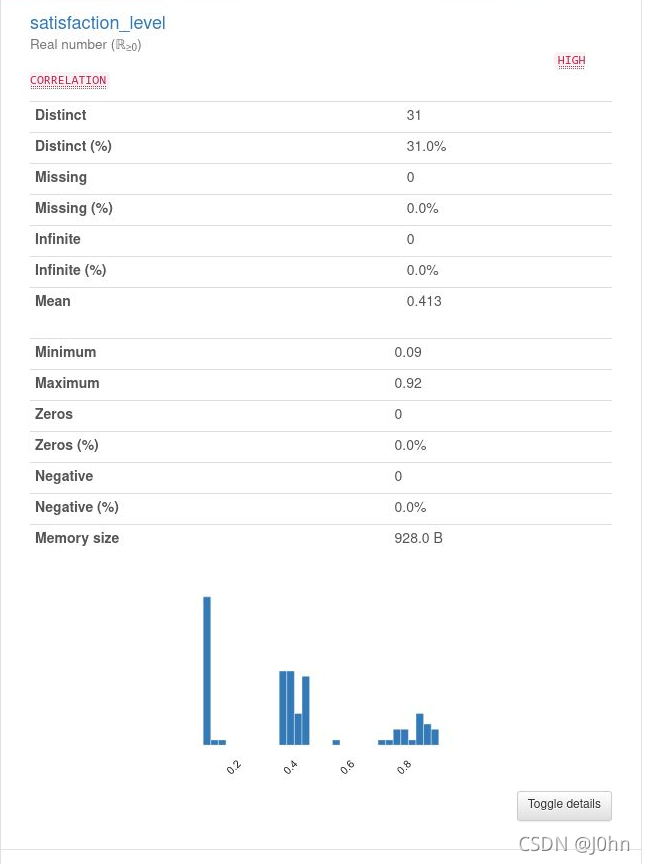
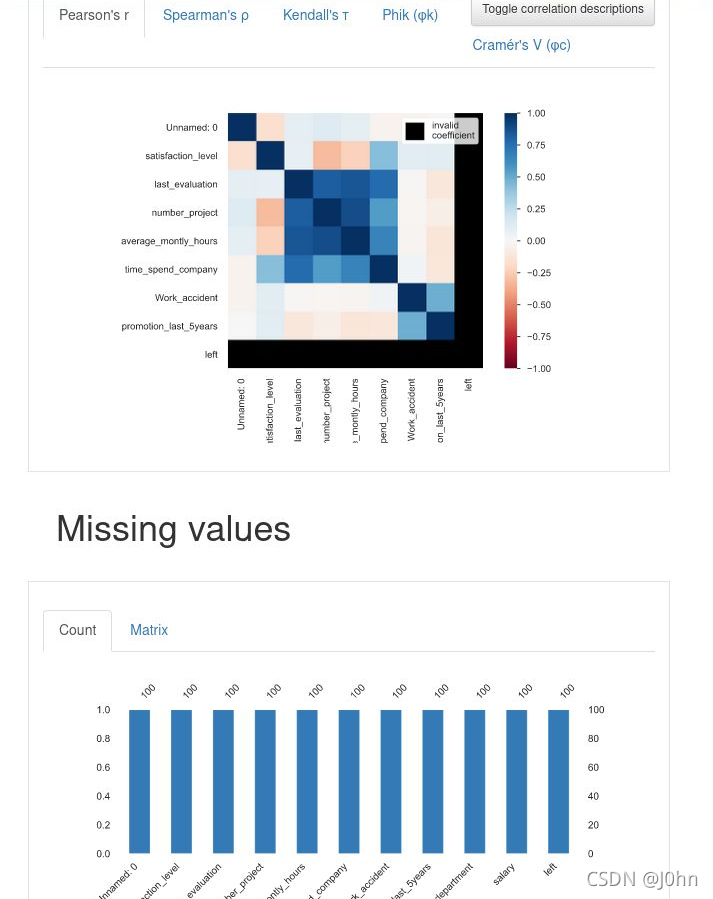
Exploratory data analysis involves the following aspects:
- Are there missing values?
- Are there any outliers?
- Are there duplicate values?
- Is the sample balanced?
- Is sampling needed?
- Does the variable require transformation?
- Should new features be added?
When developers need to access platform data and logs, they can view all system configuration files by selecting the Reproduction option. The config.json file can be downloaded at any time for further work.
(2) Machine Learning Modelling and System Logs
Once the data source has been defined and analysed, modelling can commence. The platform simplifies the modelling process, focusing on Regression and Classification—the two most widely used algorithms in data science. The major difference between these algorithms lies in the form of the loss function: quantitative outputs involve regression algorithms, which predict continuous variables, while classification algorithms are qualitative, predicting discrete variables. Developers can add additional models, such as XGBoost, SVM, and logistic regression. Finally, the developer selects an object from the dataset for prediction (currently, the project does not support cross-validation or simultaneous prediction of multiple objects). To handle this part of the process, three lists are created in the code to store the modelling parameters.

After completing the machine learning modelling, developers can select their trained models and datasets for direct use. They can also access system logs to assist in analysis and refinement. Users can specify the number of log lines to read and review, as shown below:

6. Explanation of Code for the ML Platform
Several helper functions are defined prior to the main function. For example:concatFilePath(file_folder, file_selected) is used to generate the full path to the data file, which can then be used to load the dataset.
1 | # get the full path of the file, used to read the dataset |
Read logs.log in the getModelTrainingLogs(n_lines = 10) function, and display the number of lines selected last. The user can set the number of lines:
1 | # read logs.log, display the number of the last |
Finally, for the performance of the program, the data set will be put into the cache in the function load_csv to load the data set. Repeated loading of the previously used data set will not repeatedly occupy system resources again.
1 | # load the data set, put the data set into the cache |
7. Full code presentation of the ML Analysis Platform
1 | """ |
The demo video link of the project is as follows:
Finally, this project thanks my mentor Wei Pang for academic guidance and Danny for his technology help.
Copyright Notice
This article, except for the referenced content below, is the original work of Junhao. The author retains the exclusive rights to its final interpretation. If there are any issues regarding copyright infringement, please contact me for removal. Reproduction or distribution of this content without my explicit permission is prohibited.
8. References
[1]. Kaggle XGboost https://www.kaggle.com/alexisbcook/xgboost
[2]. Kaggle MissingValues https://www.kaggle.com/alexisbcook/missing-values
[3]. MLflow Tracking https://mlflow.org/docs/latest/tracking.html
[4]. Google AutoML https://cloud.google.com/automl-tables/docs/beginners-guide
[5]. 7StepML https://towardsdatascience.com/the-7-steps-of-machine-learning-2877d7e5548e
[6]. ScikitLearn https://scikit-learn.org/stable/getting_started.html#model-evaluation
[7]. UCIDataset https://archive.ics.uci.edu/ml/datasets.php
[8]. Wikipedia https://en.wikipedia.org/wiki/Gradient_boosting
[9]. ShuhariBlog https://shuhari.dev/blog/2020/02/streamlit-intro